








Order Independent Translucency | |
| July 15th, 2006 | |
 |
I return to this problem every 6 months or so in hopes that something has changed or that maybe I wasn’t quite seeing things correctly.
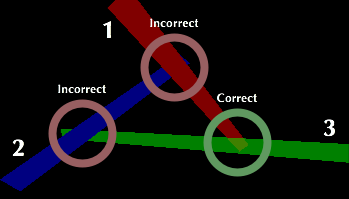 Three colored triangles with alpha of 0.5 drawn in the order of red, then blue and finally green. |
In the end I always come to the same conclusion which is that we still do not have a reasonable solution that will allow us to render multiple complex translucent objects independent of their Z order in realtime on consumer hardware. Essentially that means that when you draw translucent objects with modern graphics APIs like OpenGL and DirectX they must be drawn in a specific order from backmost object to frontmost object or else the overlapping portions will not blend correctly.
The cause of the problem is the fact that blending is an order dependent operation. Currently, games that make use of translucency ensure that all translucent objects are drawn in the correct order with respect to each other and other solid geometry through sorting. There are a lot of algorithms out there that can sort geometry quickly, but this speed usually comes at the loss of some flexibility. Also, it still takes a fair amount of work to integrate those kinds of routines into your program. At the end of the day it will start to take a very large performance toll as you increase the number of translucent objects in your scene. Another problem that object sorting does not address is when you have intersecting or complex objects that have portions that overlap other objects in certain ways. For example, if most of an object is closer to the viewpoint than another object except for a long slender portion, that long portion will not blend correctly because it was drawn after the object it is behind. These kinds of situations can often be avoided in games, but as realtime graphics grows more complex and detailed they may start to become a problem. Sometimes people use algorithms to break up their geometry into smaller parts to deal with these situations but they are very complicated and get very expensive when the complexity increases. It would be nice if we could just enable an OpenGL setting, render our objects in any order we feel like and not have to worry about whether translucent portions overlapped each other.
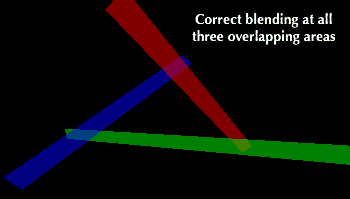 Depth peeling allows us to correctly blend un-orderable scenes. |
There are a few algorithms that allow us to use PC graphics APIs to render translcuency without respect to order such as “Depth Peeling.” If you google the OIT problem you will undoubtebly come across a whitepaper by Cass Everitt of Nvidia called “Interactive Order-Independent Transparency” (or his presentation on it) in which the technique is described. Depth peeling allows us to draw translucent objects in any order, draw intersecting translucent objects, is pixel-level accurate and can be implemented on fairly old hardware. The problem with it is that it’s slow. For every translucent layer that could ever conceivably overlap there needs to be an additional complete geometry pass if you want your results to be guaranteed perfect every time. Even if you lower the number of passes to something like the most reasonable number of layer conflicts in your situation, the toll of complete geometry passes can be very high. For this reason I have never actually seen anybody use depth peeling in a project (although there might be a project somewhere that I am not aware of).
The first version of the whitepaper used depth textures and other (really hard to set up NVidia specific) extensions but ran on the hardware that was selling at the time that it was written. As graphics cards and APIs gained fragment programability the potential for implementing depth peeling easily and having it work on a wider variety of hardware got me excited. I implemented my own depth peeler in a Cg fragment shader and texture copies. Unfortunately, even a at low viewport resolution my little FX5200 Ultra couldn’t keep up very well. I am no expert when it comes to shader optimization but I got the shader down to a fairly reasonable instruction count. Even then the power that it took to do N complete geometry passes and in turn N – 1 fragment program executions per fragment as well as all the texture copies was just too much. I again decided that the world was not ready for OIT and again put it on the side. Performance has substantially increased since then and exciting new extensions alongwith the maturity of shading languages have again increased the possibility of it becoming feasible.
Example Code
A Depth peeler implemented with GLSL and FBOs.

OIT Demo
Requires Mac OS X and support for GLSL and FBOs. (Doesn’t work quite right on ATI cards)
I have recently revisited the problem now that frame buffer objects (FBOs) and OpenGL Shading Language (GLSL) have gained traction. I was able to write a simpler fragment shader which executed more quickly and through the use of FBOs I no longer had to make expensive copies. My sample scene now runs nice and smoothly even on a FX5200 Mobile. This progress has been really encouraging. It got me thinking that for programs that can efficiently store geometry on the video card the performance hit of a geometry pass can be reduced if there is only one (at most) geometry uploads to the card but N passes of that data per frame. No doubt still VERY expensive but progress nonetheless. There are extra fragment operations executed per fragment and an additional blending phase that also take horsepower. Resource-wise, in every geometry pass there is the use of one texture unit that is taken up to reference the previous pass’ depth buffer as well as all the VRAM that the buffers take up.
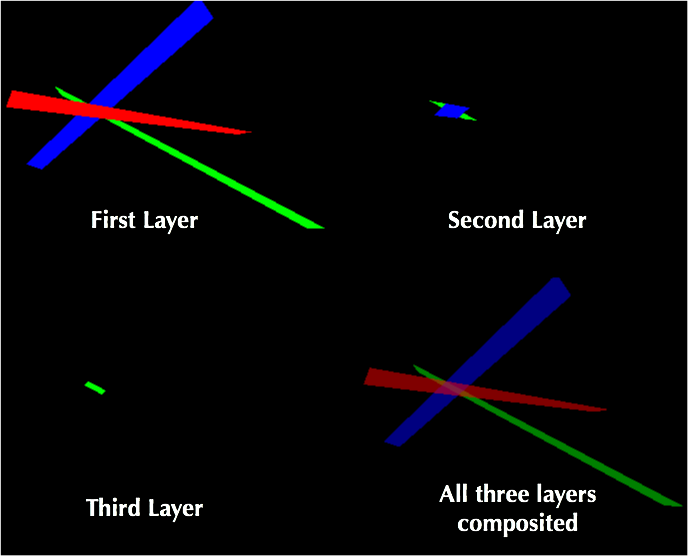 My example depth peeler at work. A GLSL fragment program correctly renders each subsequent layer after the first and then all the layers are blended together. |
A Hardware Solution
The best solution would of course be for a graphics card company to implement a solution in hardware through something like a multi-z buffer. Every time a fragment makes it through the pipeline to the Z check it would see if the fragment is father away that the one already occupying the framebuffer. If it is indeed farther and the resident fragment’s alpha is less than one then the graphics card could allocate another copy of the framebuffer (on the first hit) and repeat the same test for placement there. If the current fragment is closer than the resident one and its alpha value is less than one then it would kick the resident one down to the other framebuffer (which would cause another placement test to occur) and place itself in the topmost framebuffer. After all fragments have been processed the hardware blends the framebuffers into each other starting with the bottommost one and ending with the original top one.
In this process every overlapped set of translucent fragments would cause another framebuffer allocation. Because this can start to eat memory up very quickly, being able to choose a reasonable amount of framebuffers beforehand (like 4) and have fragment tests cap at 4 layers would be a reasonable comprimise for many situations. It would still eat a lot of memory and things can get even more expensive when you bring things like multi-sampling into the mix. In a sense the multiple framebuffers are like a big set of ordered linked lists except that the positions of subsequent nodes are known and there is no allocation/deallocation on node granularity. The great advantages of this process are that geometry only needs to be processed once, fragment processing is limited only to exactly those tests which it needs to perform and it produces per pixel accurate results. All of the operations in this process seem like they could be easily accelarated in hardware and adapted to major graphics APIs. Granted it is memory heavy and as resolutions increase so will the memory hit. However, video ram size is steadily increasing and the speediness of the algorithm combined with the ease at which it could be implemented in graphics hardware make it look like low hanging fruit to my eyes.
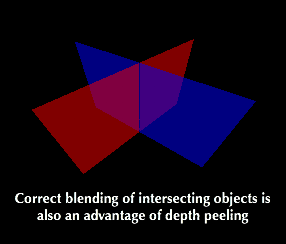 |
So why have graphics companies not made OIT research and hardware support a priority? Perhaps there is no demand because many realtime engines incorporate object ordering into their scene’s data set calculation (or just try to avoid sticky situations in the first place). For the games industry this is probably the case because of the huge dataset reduction that many undergo (calculation of the visible data set) in order to render scenes in a reasonable timeframe. What I want hardware OIT support for is small programs that want to look flashy but have quick dev time, 3D window servers which need to support huge amounts of complex and dynamic content and programs that have highly complex geometry that require a high granularity of object sorting. Maybe one day everybody will be screaming at the card makers for it but until then it will just be me and a few other people (I need to find you). Scream on, scream on…